Introduction
Zero-knowledge proof systems today often face a trade-off between speed and succinctness. STARK-based systems offer fast proving without a trusted setup, but their proofs are large. SNARK-based systems, on the other hand, produce tiny proofs that verify quickly, at the cost of a trusted setup or heavier cryptography.
At Parasol, we’re building the execution engine for high-performance perpetual futures trading on Solana, and this trade-off has been central to our design decisions. Solana offers high throughput, low latency, and a highly optimized runtime for executing transactions efficiently. In this environment, proofs must fit into Solana's transaction size (maximum of ~1,232 bytes) and compute units per transaction. As a result, generating zero-knowledge proofs compact enough to be verified efficiently on-chain becomes essential.
To address this, we designed a hybrid proving architecture: we first generate a STARK proof using FRI (for speed and transparency), and then we wrap it with a SNARK proof using KZG commitments (for succinct on-chain verification). This allows us to preserve scalability while keeping the final proof compact and efficient enough for Solana's runtime constraints.
In this article, we explore FRI and KZG commitment schemes – the cryptographic backbones of STARKs and SNARKs respectively - and discuss how combining them can support a hybrid proving architecture that balances scaling proving with succinct on-chain verification. We assume the reader is familiar with basic cryptographic primitives (hash functions, finite fields, pairings, etc.), so we focus on the advanced details of these schemes and how they apply to Parasol’s use case.
Background: SNARKs, STARKs, and Polynomial Commitments
In modern zero-knowledge proof systems, some kind of arithmetization (typically R1CS or Plonkish) is used to express the proof statement as a system of constraints over a set of polynomials. The task of the prover is to provide a succint proof that all the constraints hold, without disclosing all the witness values to the verifier.
A cryptographic commitment scheme is an algorithm with 3 operations:
- Trusted Setup - generation of Structured Reference String (SRS) by a group of trusted parties. Both the prover and verifier use SRS when creating and verifying commitments. FRI has no need for a trusted setup, KZG needs a single trusted setup for any circuit of certain size. Some other commitment schemes require a separate trusted Setup per circuit.
- Committing to the polynomial - creating a short binding representation of the polynomial without revealing it.
- Opening proof - A succinct proof that the value of the given polynomial in the given point x is equal to the given value y.
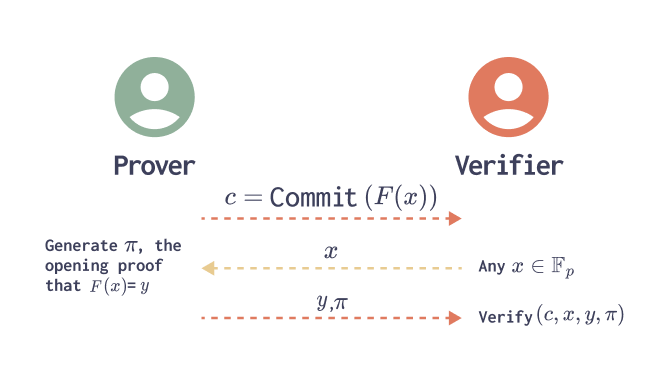
In order to convince the Verifier that all the polynomial constraints hold (i.e., that the computation was carried out correctly), the Prover commits to a set of polynomials, and later opens the committed polynomials at one or a few randomly chosen challenge points – meaning the Prover reveals the value of each polynomial at those points along with a succinct proof. The Verifier checks each opening proof, and uses the polynomial values in those evaluation points to probabilistically check the correctness of the entire computation.
FRI Commitment Scheme (used in STARKs)
FRI, or Fast Reed-Solomon Interactive Oracle Proof of Proximity, is the protocol at the heart of many STARK systems. As the name suggests, it’s an interactive oracle proof: the verifier can query oracle-like access to the committed data. In practice, FRI is made non-interactive via the Fiat-Shamir trancript.
Since FRI is a transparent protocol and does not rely on a trusted setup, we present an algorithm for committing to a polynomial of degree d, as well as an algorithm for producing the associated opening proofs.
Committing to a polynomial
In principle, an FRI-based commitment scheme could commit to a polynomial by evaluating it at every point in the entire field $F_P$ and placing all those evaluations into a Merkle tree. Conceptually, this would be perfectly sound: the Merkle root would fix the polynomial’s value at every possible input, and opening proofs would simply reveal the brach to the relevant leaf. However, such an approach is computationally infeasible in practice since the value of P is large (normally around $2^{255}$).
Instead, FRI fixes the polynomial degree bound $d = 2^r$ , and evaluates the polynomial over a larger evaluation domain of size $N = 2^R$. Let’s denote the blowup factor $ρ = N / d$. We will see later, why this blowup is necessary.
We will evaluate over the domain $Ω = 1, \omega, \omega^2, \dots, \omega^{N-1}$, where ω is the root of unity of size N. To efficiently evaluate the polynomial over Ω, we use the Fast Fourier Transform (FFT) algorithm, which evaluates the polynomial over Ω in $O(NlogN)$ time.
These evaluations form a codeword of a Reed–Solomon code. The prover then commits to this codeword by placing the evaluations as leaves of a Merkle tree and publishing the Merkle root.
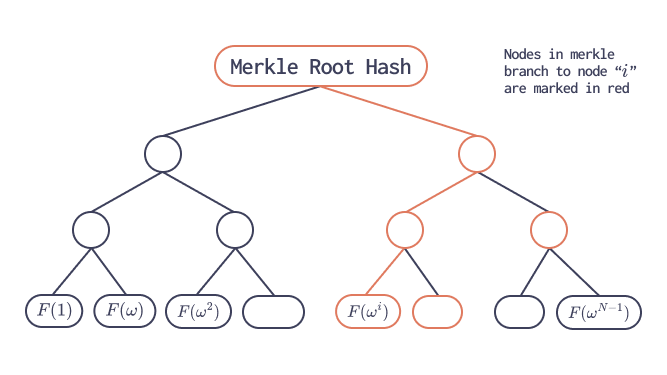
Opening Proofs
Suppose $F(x) = y$ for some challenge point $x \in F_P$. How do we provide an opening proof for any point from $F_P$, if the merkle tree allows proofs only for values in the domain Ω (corresponding Merkle branch enables the verifier to check consistency with the committed root for any value in Ω).
If F(x) = y, then polynomial $Q(X)$ exists, and has degree of less than (d-1).
$$Q(X) = \frac{F(x) - y}{(X - x)}$$
We can notice, that we don’t need to commit to polynomial $Q(X)$, if we want to evaluate it in any point of Ω, we can use evaluation proofs of $F(x)$ instead.
So how do we proof, that the degree of $Q(X)$ is less than (d-1)?
Polynomial folding
To fold a polynomial $F(x)$ , 2 operations are performed:
1. Even/Odd splitting: The polynomial $F(x)$ is split into its even-indexed coefficients and odd-indexed coefficients:
$$F(X) = F_{even}(X²) + X · F_{odd}(X²)$$
where $F_{even}$ and $F_{even}$ are new polynomials with roughly half the degree.
It’s easy to notice, that we can evaluate these polynomials over $Ω^2 = \{x²: x ∈ Ω\}$, using evaluations of F over Ω:
$$F_{even}(X²) = \frac{F(x) + F(-x)}{2}, \quad F_{odd}(X²) = \frac{F(x) - F(-x)}{2}
$$
2. Random folding: A random challenge $\alpha \in F_P$ is received from the verifier (or generated from the Fiat-Shamir transcript), and the prover forms a folded polynomial
$$F_{fold}(X)=F_{even}(X)+\alpha⋅F_{odd}(X)$$
We can evaluate polynomial $F_{fold}(X)$ over $Ω^2$ using the evaluatons of F(x) over Ω, to which the Prover have committed. If $F(x)$ truly had degree ≤ d, then $F_{fold}(X)$ should have degree ≤ d/2.
FRI Low degree test
Suppose the prover has a polynomial $F(x)$, committed to it using a Merkle tree with evaluations over a large domain Ω of size N. How do we proof that the commitment corresponds to a polynomial with degree ≤ d.
The FRI low degree test algorithm consists of 2 phases, commit phase and query phase.Commit phase can be described with the following pseudocode:
$F_0(x) = F(x)$
$Ω_0 = Ω$$for \; r = 0..log_2(N)$:
- Commit to polynomial $F_r(x)$ using a Merkle tree over evaluation domain $Ω_r$, send the Merkle root $c_r$ to verifier, where $Ω_r = \{x²: x ∈ Ω_{r-1}\}$.
- Receive a random challenge $\alpha \in F_P$ from the Verifier.
- Compute polynomial $F_{r+1}(X) = Fold(F_r(X), \alpha_i)$ .
By repeating this process for $log_2(N)$ rounds (each time halving the effective degree), the claim is reduced to one about a very low-degree (eventually constant) polynomial, which can be directly checked.
What’s left to verify is the relationship between polynomials $F_r(x)$, having the commitments $c_r$. Verifier should check that each polynomial is constructured using a correct folding equation $F_{r+1} = Fold(F_r, \alpha_i)$. This is the prupose of the FRI query phase, which can be described with the following pseudocode.
$for \; q = 0..t:$
$for \; r = 0..log_2(N)$:
- Receive a random challenge $x_r \in Ω_r$ from the Verifier.
- Send the values of $F_r(x_r), F_r(-x_r)\; and \;F_{r+1}(x_r^2)$ to the Verifier, with the corresponding Merkle paths.

The Verifier checks that the claimed relationships between $F_r(x_r), F_r(-x_r)\; and \;F_{r+1}(x_r^2)$ hold consistently. Because of the Merkle commitments, the prover cannot cheat on the values of polynomials without likely being caught (except with negligible probability). We adjust the number of of t and the blowup factor ρ to meet the required security level.
Notes on the Security analysis
Reed - Solomon code – $RS[Ω,d]$, is the set of all vectors of length N (words) corresponding to evaluations of polynomials of degree <d over Ω. It is proven, that two codewords cannot disagreeon a small fraction of the points. Since d points out of N can uniquely determine the polynomial, if polynomials are not equal, then they should disagree on average on at (1 - 1 / ρ) * N points, where ρ is the blowup factor.
Reed-Solomon conjecture (lately broken) assumes, that for any polynomial $f$ which is δ-far from $RS[Ω,d]$, $Fold(f, α)$ is δ-far from $RS[Ω^2, d/2]$, with high probability, for any δ < 1 - 1 / ρ. I.E. the folding operation preserves the distance between polynomials for any such δ. It’s obvious, that it cannot hold for δ > 1 – 1 / ρ, because if 2 polynomials matched in d points, then they will match in all the other points. Recently it was proven, that this property holds for any $δ < 1 – 1 / \sqrt{ρ}$.
In case the Prover commits to a wrong polynomial $f$ in the commitment phase instead of some polynomial $F_r(x)$, even if he/she cheats even in 1 point, the probability of not getting caught in the Query Phase after a single query is 1 / δ, I.E. after ‘t’ queries the probability of not getting caught is ${1 / δ} ^ t$.
For a 100-bit security, in case we assume the Reed-Solomon conjecture to be true, and blowup factor ρ = 2, we need t = 100 queries. In case we want proven security, then t = 200 queries will be required.
Proof size
For each of the t queries, we need to provide $log_2 {d}$ merkle branches, one per folding. Each merkle branch contains $O(log_2 d)$ nodes. So the total proof has size $O(t* log^2 d)$.
Verification speed
Verifier should check all the merkle branches, and a few simple operations over the provided values. It’s obvious, that the verifier speed is $O(t* log^2 d)$.
KZG Commitment Scheme (used in SNARKs)
The KZG polynomial commitment is a polynomial commitment scheme based on elliptic curves and pairings. It works over pairing-friendly elliptic curves like BLS12-381 or BN254.
Two groups of points on an elliptic curve are fixed: $G_1$ and $G_2$, and a target group $G_T$. Let’s denote by $\mathbb{G}_1$ and $\mathbb{G}_2$ the generator of groups $G_1$ and $G_2$ respectively.
A bilinear pairing is a function
$$e: G_1 \times G_2 → G_T$$
such that for any $g \in G_1$ and $h \in G_2$,
$$e(a*g, b*h) = e(g,h)^{ab}$$
In most modern constructions:
- $G_1 \subset E({F}_p)$
- $G_2 \subset E'({F}_{p^k})$ (twisted curve)
- $G_T\subset {F}_{p^k}^\times$
KZG produces a succinct commitment – one element from $G_1$, that binds a polynomial p(X) of degree d.
The Trusted Setup
KZG trusted setup is a one-time process of generating a Structured Reference String (SRS) using some multi party computation for a given maximal polynomial degree d.
A random $\tau \in F_P$ is generated in secret, and is destroyed after the trusted setup. The value of $\tau$ should be kept secret as the security relies on it. Multi party computation makes sure, that unless all the participants are fraudulent, no one will learn the value of $\tau$.
$SRS={\{S_i = τ^i\mathbb{G}_1} \; ,for \; i = 1..d\}, and \; \tau \mathbb{G}_2$, I.E. d values from the group $G_1$ and one value from the group $G_2$.
Committing to a polynomial
Given this SRS, anyone can commit to a polynomial $f(X) = \sum_{i = 0}^{d - 1}(f_iX^i)$ using the SRS:
$$C = F(\tau)G_1 = \sum_{i = 0}^{d - 1}\tau^iG_1 = \sum_{i = 0}^{d - 1}f_iS_i \in G_1$$
This single elliptic curve point is the commitment.
Opening proof
To verify that in some point $x \in F_p$, $F(x) = y$, similar to FRI, we will compute the quotient polynomial
$$Q(X) = \frac{F(X) - y}{X-x}$$
We need to proof that $Q(X)$ is a polynomial. For that the prover generates the proof (which is the same as committing to Q(X)):
$$\pi = Q(\tau)G_1.$$
Verifier, having commitment C to $F(X)$, $\pi$, x and y accept the opening proof if
$$e(\pi, (\tau - x)G_2) = e(C-yG_1, G_2).$$
Completeness
For the honest prover:
$$e(\pi, (\tau - x)G_2) = e(Q(\tau)G_1, (\tau - x)G_2) = e(F(\tau) - y) / (\tau - x)G_1, (\tau - x)G_2) = e(G_1, G_2)^{F(\tau) - y}$$
$$e(C-yG_1, G_2) = e(F(\tau)G_1-yG_1, G_2) = e((F(\tau)-y)G_1, G_2) = e(G_1, G_2)^{F(\tau) - y}$$
So the Verifier’s check will pass for the honest prover.
Soundness
In case the prover sends a wrong value of y, such that $y \neq F(x)$, then polynomial Q(x) will not have degree $< d - 1$. Can a malicious prover then evaluate $Q(\tau)G_1$ somehow? They will not be able to directly evaluate $Q(\tau)$, since the value of $\tau$ is not known. In order to cheat, the prover would need to provide a value $\pi \in G_1$, such that:
$$e(F(\tau) - y) G_1, G_2) = e(\pi, (\tau - x)G_2)$$
This would imply that:
$$F(\tau) - y = (\tau - x) * \pi$$
We cannot find such a value of $\pi$ since:
- $\tau$ is unknown
- Discrete log is hard
- Pairing is non-degenerate
Efficiency
The most expensive part is evaluating the polynomials as group elements $F(\tau)G_1 \; and \; Q(\tau)G_1$. Each takes O(n) scalar multiplications and O(n) group operations.
Commitment is one group element. Proof contains the value of y, and $\pi$.
Verifier checks the equality of pairings, which require 3 scalar multiplications, 2 group operations, and 2 pairing evaluations.
Trade-offs Between FRI and KZG
Having explored both commitment schemes, we can clearly see complementary strengths. Here is a summary of the trade-offs (FRI vs KZG):
- Setup and Trust: FRI is transparent – it needs no special setup, only public randomness. KZG requires a trusted setup (an SRS with secret trapdoor). If the SRS is compromised, KZG’s security breaks, whereas FRI’s security relies only on standard hash assumptions and doesn’t have this vulnerability. Transparency also means anyone can trustlessly create proofs in FRI-based systems, whereas KZG-based systems need the ceremony to be trusted by all participants.
- Proof Size: FRI proofs are significantly larger. A STARK proof using FRI can be tens of KB or more, depending on the statement. KZG-based SNARK proofs, by contrast, can be as small as a few hundred bytes. This huge gap in size matters a lot for applications (bandwidth, on-chain storage costs, etc.).
- Verification Speed: Verifying a FRI proof involves many hashing operations, while KZG is considered “super fast” in terms of verifier time, involving just a few pairings and multiplications. In practical terms, a SNARK verifier might take under 10ms even on a consumer machine, whereas a STARK verifier might take tens or hundreds of milliseconds (depending on proof size and number of queries). On-chain, those translate to different gas costs or CPU usage.
- Prover Performance: The FRI prover tends to be faster for very large circuits or computations, because it uses linear-time algorithms and can leverage a lot of parallelism (FFT over large domain, Merkle tree construction). KZG-based proving (e.g. in Plonk or Groth16) involves running large FFTs and performing multi-exponentiation for all polynomial coefficients to compute commitments, which can become a bottleneck. For example, proving a huge computation might be more feasible with a STARK (if memory isn’t an issue) because of lower constant factors, whereas SNARK provers might struggle with memory and multi-exp time.
- Security assumptions: FRI’s security is in the random oracle and hash collision resistance – well-studied, standard assumptions – and is believed secure even against quantum attacks (no known efficient quantum algorithm breaks hash-based soundness). KZG’s security rests on the hardness of discrete logarithm problem over elliptic curves. It’s not PQ-safe. This means if one is designing for the long horizon (post-quantum world), a FRI/STARK approach is preferable unless post-quantum replacements for KZG are used.
In summary, FRI vs KZG is not “one is better than the other” – it’s a classic trade-off scenario. FRI gives us trustless setup and potential speed at the cost of proof size and verifier complexity, whereas KZG gives succinctness and speed for the verifier at the cost of a trusted setup and heavier prover work. This is precisely why combining them can be so powerful: we can use each where it’s strongest.
Hybrid STARK–SNARK Prover Design
To get the best of both worlds, we can compose a STARK with a SNARK. The idea is straightforward: use a STARK to prove the statement in principle, then use a SNARK to prove succinctly that the STARK proof is correct. This yields a final proof as small and easy-to-verify as a SNARK, while retaining the STARK’s scalability and transparency in the proving phase.
Conclusion
By combining the FRI and KZG commitment schemes, we achieve a hybrid STARK–SNARK proof system that is both fast and succinct. The FRI scheme contributes a high-throughput, transparent proving process (ideal for massive computations without needing trust in setup), and the KZG scheme provides a compact proof for easy verification. We used FRI based STARK prover to handle the “heavy lifting” off-chain and KZG based SNARK prover to ensure the final proof is minimal for on-chain verification.
The context of Solana made these choices especially clear – with roughly ~1 KB of space and a few hundred milliseconds of compute available per transaction, the only viable way to prove complex statements was to keep the on-chain part as small as possible. We assume basic cryptographic soundness (collision-resistant hashes, secure pairings, etc.), and accept one trusted setup for the SNARK.
More broadly, this architecture highlights how different cryptographic primitives can be composed to build practical zero-knowledge systems for high-performance use cases.
Follow us on X for updates on our research and progress building the engine to perpify internet capital markets.