Perp markets at scale need high-frequency, predictable execution that keeps up with how traders actually trade. The cleanest way to deliver that is a high-frequency CLOB - the most capital-efficient market structure available: tighter spreads, deeper liquidity, real price discovery.
CLOBs are also the hardest to prove, and that's where things get interesting for our ZK engine to accelerate perpetual markets on Solana. Proving that a CLOB transitioned correctly from one state to the next means handing the verifier two things: the order book before, and the order book after.
For a real perp DEX with thousands of resting orders across hundreds of price levels, the verifier input alone would be larger than most proof systems can handle efficiently. The standard fix is well known: instead of passing the full data, commit to it with a short hash and let the program work with the original data internally, proving along the way that what it touched matches the commitment.
Merkle trees (see earlier post) are the standard tool for this. For most workloads, a generic Merkle tree is enough. For a high-frequency CLOB, it isn't. The access patterns are too specific, the operations touch too many records per transaction, and the cost of treating a Merkle tree as a black box compounds fast.
We had to modify the structure. This piece walks through what we changed.
Generic solution: Merkle trees
How does packing everything into a Merkle tree work? We replace all input and all output by top-level hashes for the respective tree (or, we might as well hash those two hashes and get a single hash in the public input). Whenever the proved program needs to access some of its input or output data for proof generation, the prover fetches it from the actual input or output.
Yet, to prevent the prover from cheating, the version of the program that uses a hash digest instead of explicit input/output includes an additional sequence of operations. Every fetched piece of data is proven to be compatible with the commitments which are shared as public input. This usually involves computing a certain number of hashes. Thus, we trade input length (which is now short) for program complexity (which now becomes bigger).
Merkle trees are actually already a sophisticated trick: the most naive solution would have been to hash the entire input/output as a single sequence. Yet, doing so for something as big as an order book full of orders would result in a program that spends most of its time hashing its input and output only to perform several operations on a meager fraction of the whole dataset.
Having specially tailored data that contains only the specific parts touched by operations creates unnecessary complications, because it requires too many different program setups, so Merkle trees are a good compromise: they can store the entire order book, while data access remains relatively cheap.
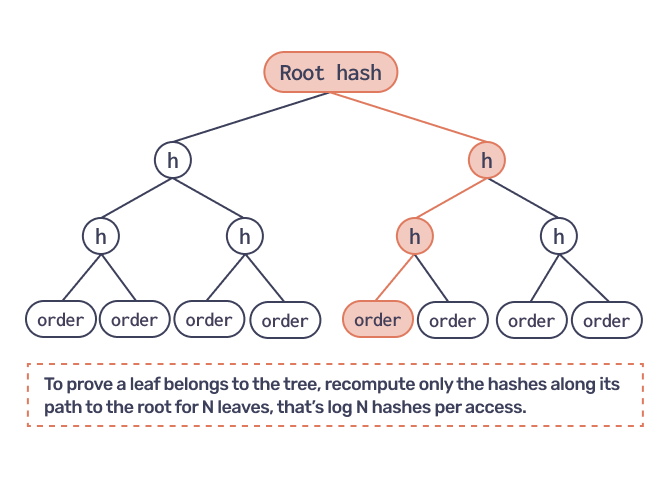
To be specific, for every piece of data we want to access, we have to compute a number of hashes, that is logarithmic in the total data length. That is, for a total of 1 024 records accessing one record costs 10 hashes, and for a total of 1 048 576 records - 20 hashes per record accessed.
This is a good starting point, but CLOB operations usually touch upon several records and when access costs multiply by the number of records accessed, proofs are getting longer and costlier to generate. Yet, taking into account the specific patterns of data access for a CLOB, we can modify and extend the basic Merkle tree construction to keeps data access costs low.
Tailoring Merkle trees for CLOBs
While a perp DEX is certainly more than simply CLOBs, we focus here only on CLOB storage optimization, as this is our main performance battlefield.
The following ideas were used to make Merkle trees meet the needs of a CLOB:
- Order storage gets split into two primitives: a price level index and level queues. That is, the orders are grouped by their prices into levels and each level is stored as a queue of orders. This design has two advantages. First, our engine runs the CLOB code twice — once in a non-ZK environment to give traders a fast result, and once in a ZK environment to generate the proof. Using the same storage structure across both paths keeps the two executions aligned. Second, it lets us combine the benefits of indexing with a dedicated storage primitive for the queue at each level.
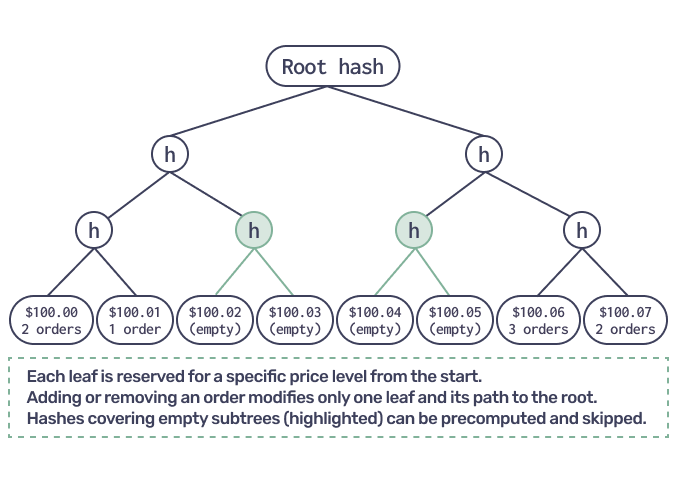
- Prices serve as keys in an indexed Merkle tree. The basic approach to Merkleizing data is just to construct a binary tree over it and compute all hashes. Doing so for order price levels would imply that either we have to store them according to creation time, which is impractical for order matching, or we have to recompute a big part of the tree whenever and order is inserted “into the middle”. A solution is to have an indexed tree. Each leaf is dedicated to a specific price value from the beginning and most branches contain no data at all. Whenever we want to add or remove an order from a specific level, we just modify it without touching any other leafs. There is an order on orders (no pun intended) and we always know where to look for orders of a specific price. The cost of this solution is to have the same number of hashes per access to compute, regardless of whether we have few or many orders in our order book. Yet for a functioning order book with many orders in it, this is negligible. Another easy optimization is that we can precompute hashes that correspond to empty subtrees. Thus, whenever we need to show that there are no orders of a specific price, we might skip entire subtrees instead of looping through their leaves. That saves our resources: we have fewer hashes to compute.
- At the queue level, different storage primitives can be used. Evidence suggests that most non-empty order queues contain just a single order. For cases like this we don’t really need an entire Merkle tree. Naive hashing of the entire queue is a much better solution. This might produce complications if a specific level queue is suddenly flooded by orders, but we have some tricks up our sleeves for that case. The basic implementation uses plain hashing. If a queue suddenly floods with orders, we can swap in a hybrid that mixes naive hashing with just enough Merkleization.
- Internal nodes cache metadata, not just structure. The hash at in internal node of a Merkle tree can tell us that the subtree has no orders. So we asked: why stop there? CLOB operations can benefit from other information about orders in a subtree, besides the fact that there are no orders there. So, we have extended Merkle tree internal nodes to store more information: the best available order price in the subtree and the total value of all orders in a subtree. Knowing these parameters avoids looping through the orders, thus saving hash computations and reducing data access burden for our CLOB operations.
- We group reads and writes. Each data access results in a number of hashes to be computed. Yet, many of those hashes tend to repeat. When you compute hashes along a tree branch, the upper hashes — closer to the root — tend to be shared across many branches. So, why recompute them every time? We pushed this further: our program tracks all its reads and all its writes from/to the CLOB and then forms the subsets of accessed leafs and internal nodes. Then, instead of recomputing one branch at a time, it recomputes one root hash for this entire subtree, fetching only hash data about everything that is outside of the subtree that interests us. Thus, we actually compute the root hash before (all the reads) and the root hash after (all the writes) and we don’t interact with the tree in-between. Everything we need is loaded into program memory via reads, manipulated there and finally brought back to the tree via writes. This is probably close to the minimal number of hash computations for a given read/write access sequence.
Final thoughts
The improvements above target order book storage specifically, but the same primitives extend to other state our engine has to handle: users, markets, and so on.
Everything is eventually hashed into a single root that commits to the full state at a given moment. The data itself gets published to a data availability layer, so anyone can verify it matches the committed root.
Proofs stay succinct. Programs stay lean. Transparency stays intact. For Parasol, this is what makes ZK execution at the throughput perp markets demand actually viable. A generic Merkle tree gets you part of the way. Tailoring it to how a CLOB actually behaves is what makes the difference between a system that proves correctly and a system that proves correctly fast enough to matter.